Signal-driven health monitoring for HNSW indices w/ pgvector
Originally posted on Medium.
Read the original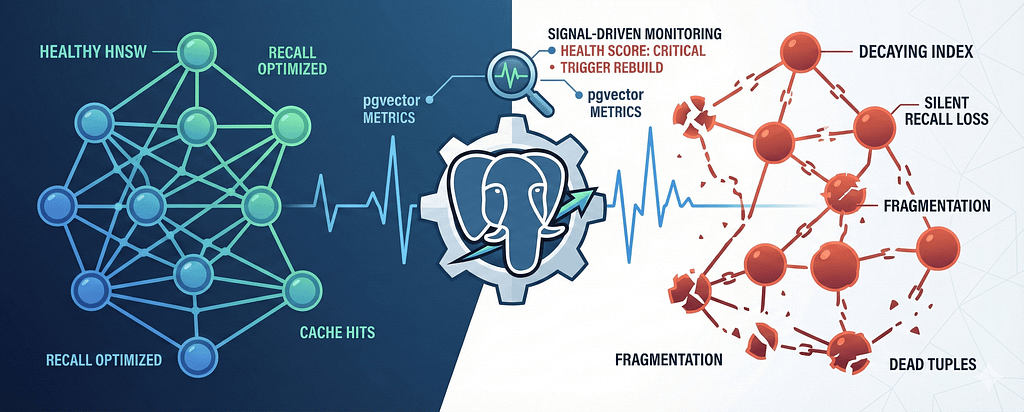
Vector search in PostgreSQL has come a long way, and pgvector makes it simple: insert embeddings, create an HNSW index, and run ANN queries. At least for a while.
As our system scaled across stores, regions, and product volumes, something became clear: HNSW is not “fire and forget.” Indexes age. They bloat. They fragment. They silently lose recall. When they degrade, search results degrade too. Sometimes this happens gradually, sometimes catastrophically.
For months, we assumed our approach was fine: rebuild indexes every night at 1 AM, after product imports, and after ingesting new embeddings.
It felt safe. It was absolutely not.
When Scheduled Rebuilds Turned Into a Problem
Our first attempt at maintaining HNSW indexes was a classic ops mistake: periodic work instead of condition-based work. Every night, every tenant, every index. No intelligence. Just execution.
And here’s what happened:
- We rebuilt indexes that had zero new writes — massive waste of compute + IO
- Large tenants saw daily index decay — recall dropped, latency increased
- Crash mid-rebuild left an index invalid but still present — PostgreSQL stopped using it entirely
- Replicas diverged from primaries — queries returned different ANN results per region
The worst case was the INVALID scenario. A configuration change required a Postgres restart. This restart happened during a CONCURRENT index creation. In Postgres, when a CONCURRENT index is being built, it is first added to the system catalog in an INVALID state. The system must then complete two full table scans to build and validate the index. If Postgres is restarted before these scans complete, the index remains present but stuck in an invalid or corrupted state. The result: an index that looks present but is unusable, and no one notices until search quality degrades or anomalies are detected.
That incident is what forced a rethink.
We didn’t need scheduled rebuilding. We needed index health monitoring and to rebuild only when necessary.
What Does “Healthy” Mean for an HNSW Index?
B-trees give you clear signals: bloat, dead tuples, page churn. HNSW is structure-heavy. It is a layered, navigable small-world graph. Its quality depends on:
- how many vectors have been reinserted or replaced
- how many nodes reference deleted or obsolete embeddings
- how well graph layers remain navigable under memory pressure
- whether the index still fits inside the buffer cache or spills to disk
There is no single metric like fragmentation percent.
So we built one.
We created a three-metric model that produces a single health score for every HNSW index:
- Dead tuple ratio — Signals vector churn + unpruned graph nodes
- Cache hit ratio— Indicates memory residency vs IO-bound index walks
- **Bytes per vector (bloat heuristic) —**Detects graph overgrowth + wasted structure
If an index inflates, loses cache locality, or accumulates dead references, search degrades. Not instantly but inevitably.
And critically, PostgreSQL already exposes everything you need to measure this.
Metric 1: Dead Tuple Ratio
Dead tuples happen when embeddings are rewritten, deleted, or replaced. In B-trees, that’s annoying. In HNSW, dead nodes remain in the graph like abandoned intersections. Search hops still cross them. They increase hop count. They widen the beam width. They reduce recall.
Even without deep internals, PostgreSQL gives a usable surface:
dead_tuple_ratio = n_dead_tup / n_live_tup
If that ratio climbs toward 10–15%, rebuilding pays measurable returns. Dead tuples are a silent killer. We use the following query in production.
SELECT
relname AS table_name,
n_dead_tup,
n_live_tup,
ROUND((n_dead_tup / GREATEST(n_live_tup, 1)::float) * 100, 2) AS dead_tuple_ratio_pct
FROM pg_stat_all_tables
WHERE relname = 'your_embedding_table_name';
Metric 2: Cache Hit Ratio
This one surprised us.
We always assumed index performance dropped because the index itself degraded.
But very often, performance dropped because the index no longer fit in memory.
When HNSW pages are evicted from shared_buffers, traversal becomes disk-bound. ANN is fast only when the graph fits in RAM. Once it doesn’t, vacuum and reindex are not just cleanup. They restore performance.
SELECT
indexrelid::regclass AS index_name,
idx_blks_hit,
idx_blks_read,
ROUND((idx_blks_hit * 100.0 / GREATEST(idx_blks_hit + idx_blks_read, 1)), 2) AS cache_hit_ratio_pct
FROM pg_statio_user_indexes
WHERE indexrelid::regclass::text LIKE '%hnsw%';
We treat anything below 90% hit ratio as a yellow flag. Below 75% is red.
Not because slow scans happen.
Because the planner may stop using the index altogether.
Metric 3: Bytes per Vector
This is our approximation of HNSW bloat.
We know the expected size of an embedding dimension: a 1024-float vector is about 4096 bytes of storage plus HNSW structural overhead. If observed bytes per vector drift from baseline, the index grows inefficiently.
WITH idx AS (
SELECT c.relname AS index_name, pg_relation_size(c.oid) AS index_bytes
FROM pg_class c
JOIN pg_index i ON i.indexrelid = c.oid
WHERE c.relname LIKE '%hnsw%'
)
SELECT
index_name,
pg_size_pretty(index_bytes) AS index_size,
(
index_bytes / NULLIF(
(SELECT reltuples FROM pg_class WHERE relname = 'your_embedding_table_name'),
0
)
) AS bytes_per_vector
FROM idx;
**Example symptom:**We expect 5.0KB per vector and see 9.2KB per vector being stored. This equals bloat. Rebuild justified.
It’s not perfect, but it correlates strongly with real-world recall degradation.
The Health Score
Instead of binary rebuild vs no rebuild, we compute:
score = dead_score * 0.4 + cache_score * 0.4 + bloat_score * 0.2
Weighting rationale:
- Dead tuples = recall degradation → heaviest signal
- Cache residency = latency + planner reliability
- Bloat matters, but less across large embeddings
When a score dips below our threshold, rebuild is triggered only for that index.
We stopped rebuilding everything. We started rebuilding only what needed it.
Like the writing? Follow product development at Layers

Jake Casto · Founder, Layers
Jake Casto is the founder of Layers, the enterprise search and merchandising platform built for Shopify Plus. He previously co-founded Proton, a Shopify Plus engineering studio that shipped more than 400 storefronts, where Layers began as an internal tool for a problem that kept repeating. He writes about search infrastructure, performance, and the engineering behind discovery at scale.
Connect on LinkedIn